要看懂一幅中国画
并不容易
审美能力需要长期的积累和训练
那么,ai能看懂中国画吗?
当你让ai解读一幅山水或人物画
它可以生成一篇长篇大论
但问题是——
它是真的看懂了,还是只是看起来很懂?
北京大学「智镜」项目
就是为了解答这一个问题
给ai建了一套“中国画考试系统”
ai来答题,人类专家来阅卷
通过“考试”排名
不仅能客观比较不同ai的中式审美水平
也能找出它们在历史背景、文化常识方面的错误
从而为ai的本土化调优指明方向
(文末有“考官”体验入口!)
「智镜」项目属于北京大学,它乃是把构建“中国传统审美”多模态大模型(llm)评测基准当作目标的首个学术平台。,该项目是由北京大学艺术学院以及北京大学计算艺术实验室携手研发的,其目的在于为aigc的审美评测还有质量控制去提供有着中国文化深度的量化数据支撑 。
大模型是否真正理解中国艺术?
「智镜」起始于2025年3月,它源自于对大模型审美能力的思索,北京大学艺术学院李洋教授团队针对全球范围内的大语言模型开展了广泛的调查研究,研究发觉,当下主流评测体系大多是基于通用任务以及西方美学框架,然而中国古代艺术体系成熟且内涵繁杂,却长久缺少一个能够对ai表现进行系统评估的标准。
所以,于北京大学 - 东湖高新区国家智能社会治理实验基地,在“人文社科项目群”课题予以支持的状况下,北京大学艺术学院「智镜」项目组正式组建完成。李洋教授团队,首先针对大语言模型,是否会改变人的审美体验,做了专题调研。团队从2016年到2024年,撰写的20000多篇报告入手,涉及2700所高校大学生。不仅发现,大学生使用大语言模型的情况,在2023年和2025年,有了明显上升。更分析出,他们运用大模型进行表达时,出现了个人体验反思的外包,与审美升华的悬置。在“无痛自我感知”与“理论反思”两个维度上,都体现出明显的变化。
于是,“智镜项目”因大语言模型的审美问题而出现产生进展,依据北京大学计算艺术实验室跨学科的优势条件,试图去构建一套扎根于中国自身美学传统的评估体系,把意境、气韵、神采等中国审美范畴转变为能够被ai测试以及迭代的具体指标 。
如何量化“中国美”?
“智镜”有着一种思路,这种思路实际上是比较简单的,那就是要让那些真正对中国艺术有所了解的人,去判别究竟哪个ai所表达的内容会更好 。
要实现这个想法,需要解决三方面的问题。
首先,用哪些画来测试?
当做数据源,“智镜”建立了包含18,000 张小中国艺术图像数据库,是以古代书画当成核心,之后渐渐扩展到好多门类的;每一件作品同时整理创作背景、风格流派、文化寓意、评论文献等文本信息,从而形成“图像 文本 文化”三位一体的数据基础。
其次,测哪些模型?
与、、、、、meta、qwen、thudm、x.ai之类机构相联系的28个多种模态的大模型,已被平台整合起来,于统一的接口、同样的作品、一致的指标状况下,开展不间断的评测以及不断变化的排名活动,并且一直在进行着!
最后,找哪些专家?
在智镜项目这儿,有70余位已完成两轮评测的评审专家,他们来自北京大学、清华大学、南京大学、浙江大学、中央美术学院、中国美术学院、南京艺术学院、河北美术学院等高校与研究机构,这些评审专家是中国古代美术史与相关方向的学者和博士生,他们负责搞完成作品对战和测评,还要对大模型的审美表现给予反馈和评价。因为这个,才成为了大模型审美排行版的基础数据。
在第三期测评当中,四川美术学院加入了智镜计划,广州美术学院也加入了智镜计划,鲁迅美术学院同样加入了智镜计划,湖北美术学院以及其他更多院校跟着加入了智镜计划,并且,30多位在高校任教的艺术史学者共同组成了测评团队。
开始对战!
智镜搭建起了一个对战的平台。ai是对战选手,专家作为裁判。
经由网页端进入系统的专家,其能够依据时代、题材这种类别去浏览作品,进而查阅实时模型排行榜,选定作品之后,系统便会自动载入图像以及元数据。换句话说,要使得大模型围绕着中国审美呈现出激烈竞争态势!

智镜项目在评测模式方面,给予专家这样的选择,即国际大语言模型评估的两种通行对战形式,其中一种是匿名随机对战,另一种是由测评人指定两个模型进行对战,然而对战形式为“盲评”,也就是不会给大模型提供除图像理解之外的任何信息。

被选定之后,这两个模型会各自针对这幅作品开展解读工作,进而生成一篇篇幅较长的文章。那专家要去选择偏好选项(a更好 / b更好 / 两者差不多 / 两者都不好),而且能够从作品信息准确性、构图分析、笔墨技法、意境解读等诸多维度填写简要的理由。
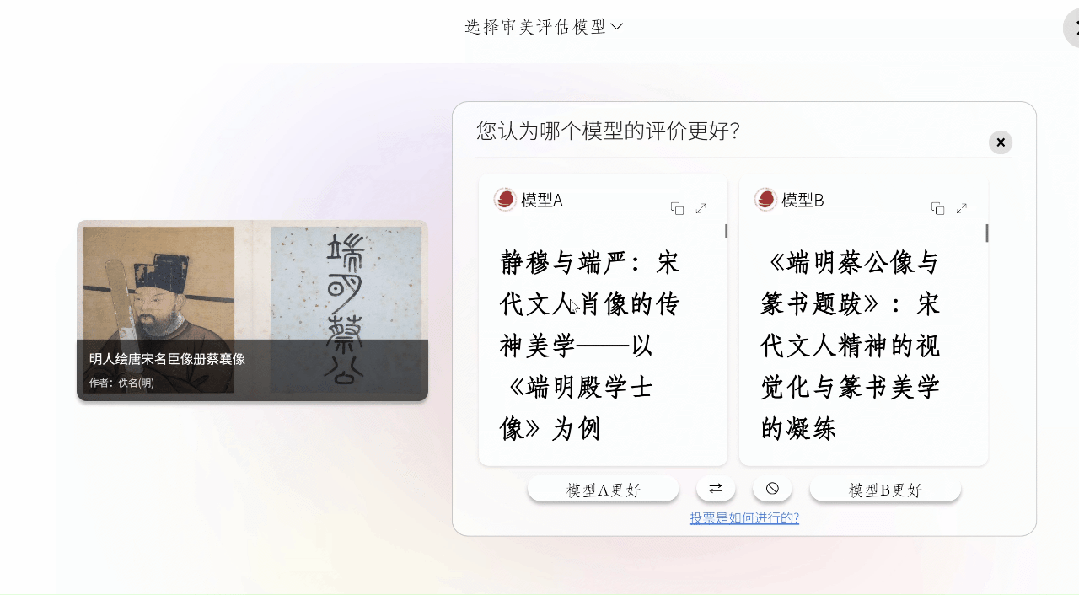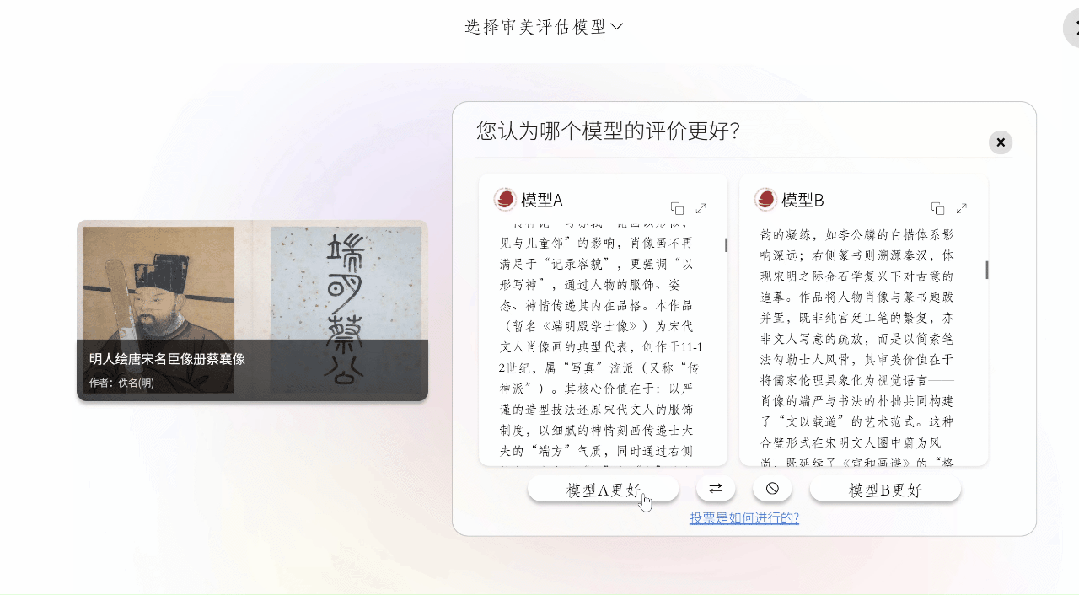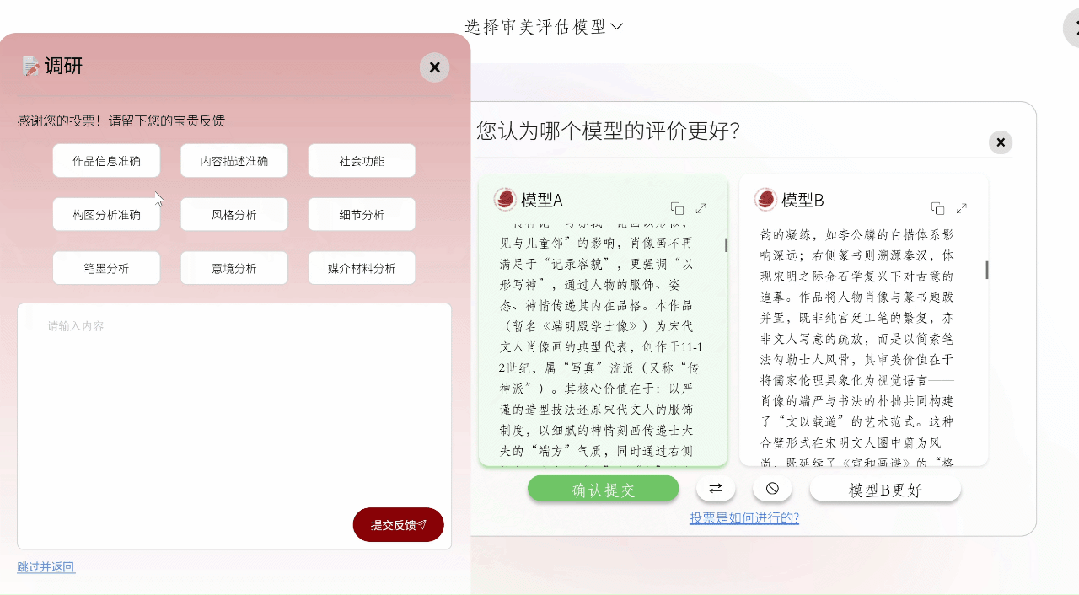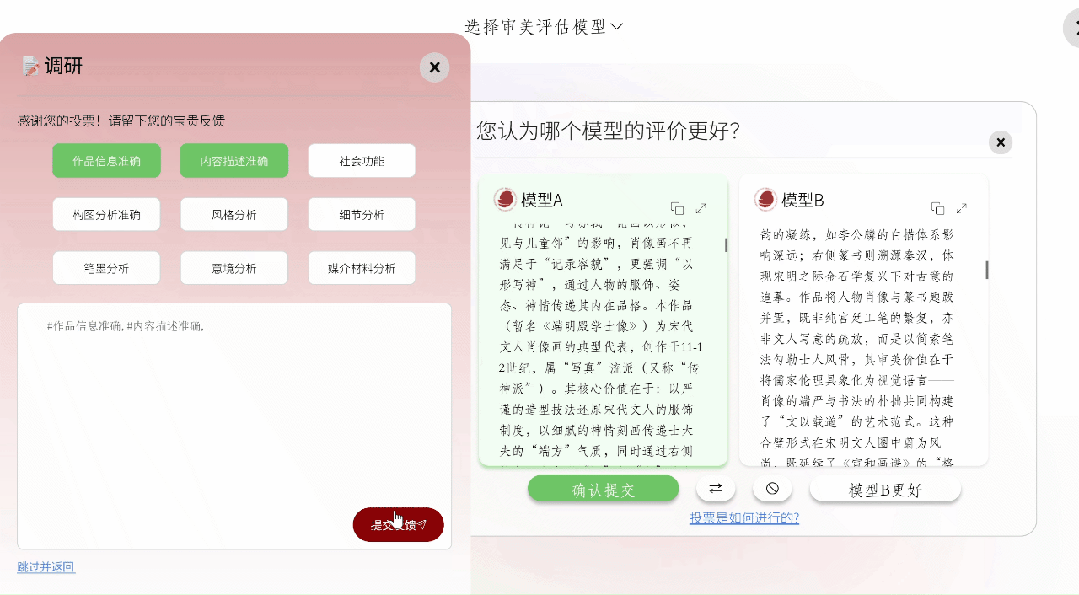
依循专家们所给出的投票结果,系统凭借–terry以及elo算法,在实际时间当中对模型排行榜进行更新。
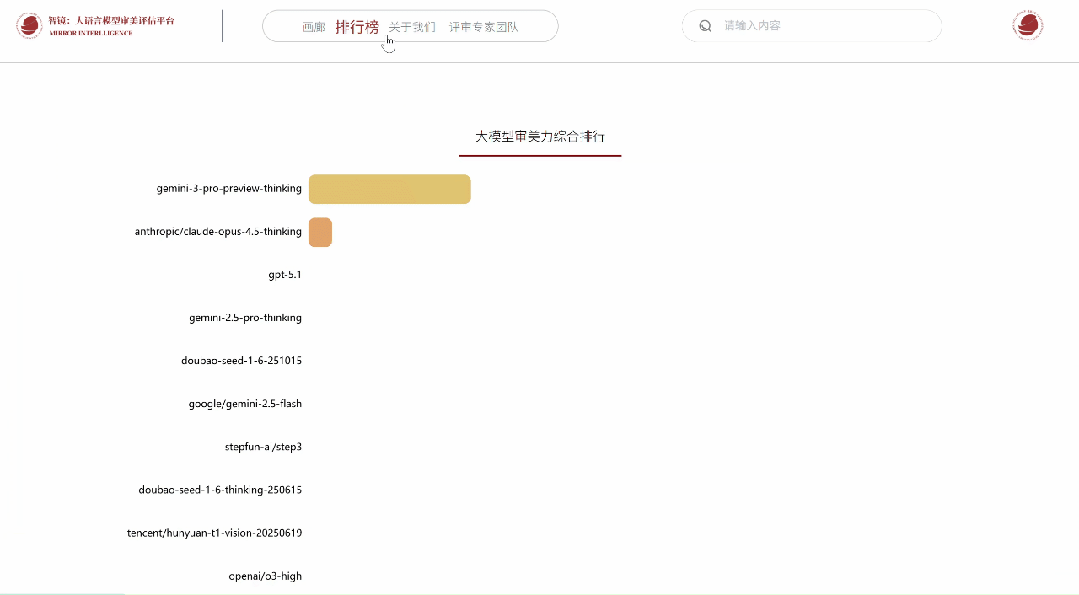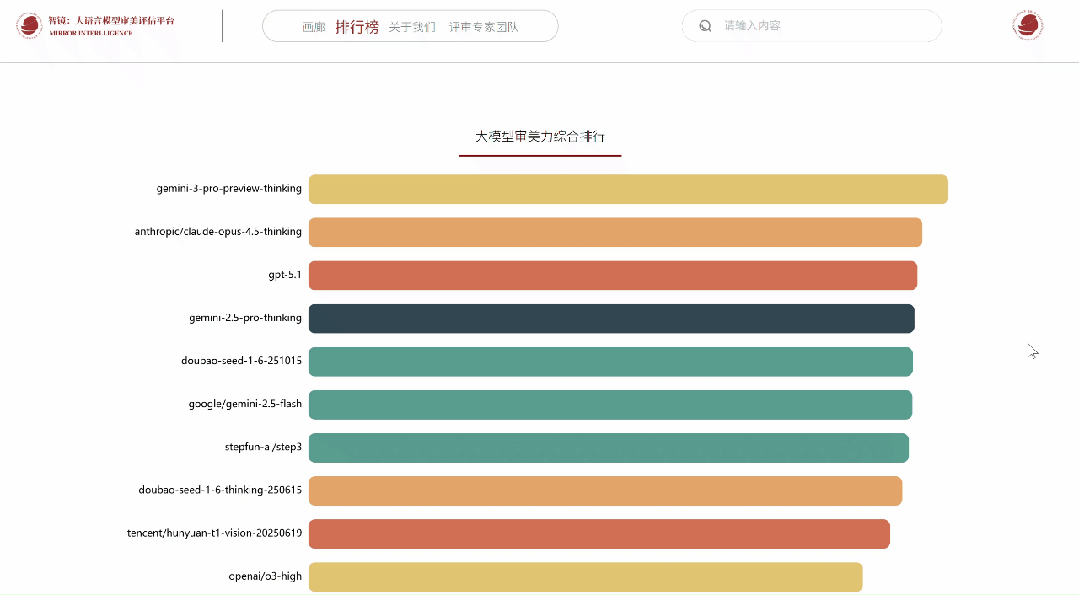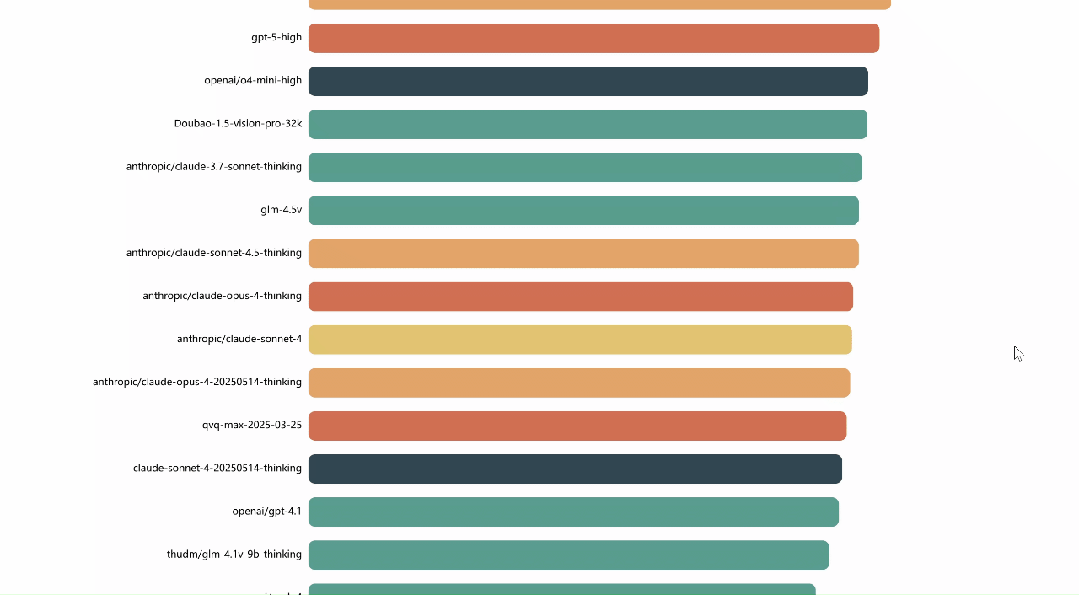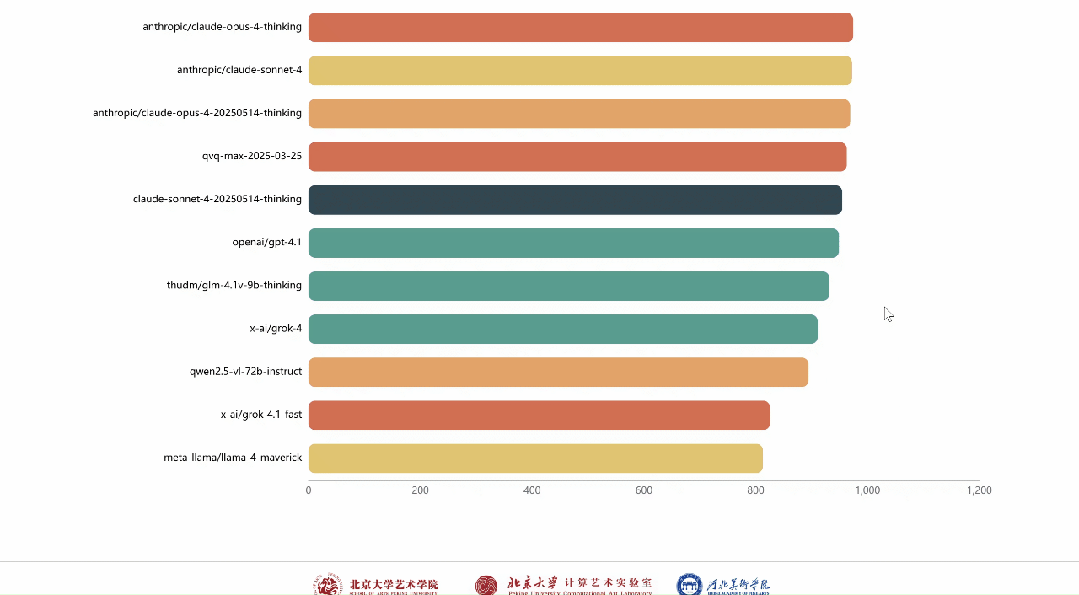
作为专家,可在个人中心查看历史投票记录与参与详情。
体验入口
「智镜」项目当前只对邀请的专家开放注册
计划于2026年5月正式对公众开放
目前,公众可通过以下链接体验评测:
(复制链接在浏览器打开,或点击“阅读原文”)
未来规划
「智镜」项目,首次对多模态大模型评测基准立足中国美学传统做了系统构建,使得气韵、意境等范畴成了可量化维度。与此同时,把美学理论转变成了可持续使用的评测系统,能支持不同模型于同一标准下反复进行测试,还为后续研究供给基础设施。除此之外,凭借识别模型在审美范式、历史背景、文化常识等方面的典型错误,给模型的本土化调优给出明确方向 。
「智镜」于未来时,会不断去拓展其评测体系的深度以及评测体系的边界,在现有的图像测评为基础的情形下,此项目的第二时间阶段打算一步一步地引入文本,引入音乐,引入视频以及引入三维场景等多种模态的内容,以此去考察大模型在不一样的媒介当中的审美理解能力以及审美生成能力 。
于评测机制方面,项目会进一步去完善专家参与结构,除博士生以及青年学者外,项目的第二步,要邀请艺术史教授以及美学学者来组成专家委员会,通过完善理论框架以及评分校准,进而进行测评打分;第三步时,项目会邀请中国的艺术家开展测评,从创作实践的角度对评测结果予以复核与修正。测评专家团队会从国内延伸至国际专家团队,以此使评测结果更为客观公正。智镜项目还打算对公众开放,邀请所有关注大语言模型审美问题的网友加入评测打分 。
与此同时,“智镜”会以开放的姿态来推进生态的共同建设,去联合高校、科研机构以及相关行业的力量,频繁地发布审美评测结果,着手开发面向公众的互动产品,渐渐把平台构建成一个连接技术、文化与社会的公共空间啦。
为ai“照镜”
为 ai“照镜”,是「智镜」项目的核心隐喻。
它期望构建起连接大众、专家以及ai的桥梁,通过学者与艺术家的专业评审,把中国传统美学转变为算法能够理解的评估体系,同时凭借可视化的榜单以及交互界面,向公众清楚呈现ai对中式艺术的认知水平,推动技术在多方对话里持续校准,达成对中国之美的守护与创新诠释,“智镜”项目留意中国审美在人工智能时代是怎样被吸收和表达的,还有中国审美的传承与安全。
「智镜」这个名字,其所蕴含的意义十分深刻,它不仅涵盖着审美观照方面的意思,还包含着技术自反的思索。
项目发起人李洋教授表明,“智镜”的直接契机,源于对“ai审美污染”的警惕,当生成情况变得太过轻易时,人们也有可能渐渐把想象以及体验外包给机器,进而陷入一种无意识的审美退化状态 。
在他的观点里,于ai时代,我们依旧要讲美,人文学科在技术迅猛发展的进程当中,有责任提出清晰且有立场的价值判断,而在北大,这一责任格外深刻且迫切。
因此,「智镜」不单单是一项评测类工具,更存有这样的期望,它要成为一个倡导处于ai时代下的审美价值的关键所在,还要成为推动技术朝着善方向发展的关键所在,更要成为弥补全球知识生产以及审美体系里不平等现象的重要节点。
在未来,那是个被算法以及生成内容持续围绕的未来里,“智镜”要努力守住的东西,是什么呢,是人类去感受世界的能力,还有,人类理解美的能力,还要说的是,人类创造意义的那种能力,与此同时,而它所映照出来的内容,是什么呢,是看我们在技术那如洪流般快速涌动的形势之下,是不是至今仍然心甘情愿地为“美”留存下判断以及思考的空间句号。
来源 | 北京大学融媒体中心、北京大学艺术学院
采写 | 张祺祺、来家君、徐周雨宣
排版 | 顾馨月
编辑&责编 | 岁寒

















尊龙凯时注册▷www.pmceo.com